

今回はpytorchとgoogle colabを用いて物体検出モデルを実装しようと思います。
Faster-R-CNN、YOLO、SSDなど様々な物体検出モデルがありますが、今回はFaster-R-CNNを使用していきます。
Faster-R-CNNはTwo-Stage法をとっており、物体が写っている領域の候補を検出するネットワーク(Region Proposal Network)と、領域候補のカテゴリを識別するネットワークが直列に実行されます。
そのため、領域抽出とラベル識別を同時に行うSingle-Stage法のYOLOやSSDと異なり、処理速度が少し遅くなっています。
一方で、Faster-R-CNNの特徴としてRPNを採用しているため、候補領域の数を柔軟に制御できることに加え、小さい物体の検出も得意です。
データセットはNIH臨床センターが提供している胸部X線データセットを使用します。

物体検出モデル(Faster-R-CNN)学習編
1. データの確認
はじめに、google colabのGPUのスペック確認、およびgoogle driveをマウントします。
!nvidia-smi
from google.colab import drive
drive.mount('/content/drive')Thu Dec 21 06:14:27 2022
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla V100-SXM2-16GB Off | 00000000:00:04.0 Off | 0 |
| N/A 31C P0 23W / 300W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
from google.colab import drive
drive.mount('/content/drive')次にドライブ内のファイルのパスを指定し、必要なフォルダを作成していきます
import os
base_path = '/content/drive/MyDrive/x_ray_chest/results/faster_r_cnn'
ver = 'v1'
# 新しいフォルダを生成
weight_folder = 'weight'
train_folder = 'train'
test_folder = 'test'
test_img_folder = 'images'
weight_folder_path = os.path.join(base_path, ver, weight_folder)
train_folder_path = os.path.join(base_path, ver, train_folder)
test_folder_path = os.path.join(base_path, ver, test_folder)
test_img_path = os.path.join(base_path, ver, test_folder, test_img_folder)import sys
def create_folder():
if os.path.exists(os.path.join(base_path, ver)):
sys.exit()
else:
os.mkdir(os.path.join(base_path, ver))
os.makedirs(weight_folder_path)
os.mkdir(train_folder_path)
os.makedirs(test_img_path)
# フォルダ生成関数の呼び出し
create_folder()「BBox_List_2017.csv」「Data_Entry_2017_v2020.csv」の中身を確認していきましょう。
from glob import glob
import numpy as np
import pandas as pd
import seaborn as sns
BBox_List_path = '/content/drive/MyDrive/x_ray_chest/BBox_List_2017.csv'
Data_Entry_path = '/content/drive/MyDrive/x_ray_chest/Data_Entry_2017_v2020.csv'
BBox_List_df = pd.read_csv(BBox_List_path)
Data_Entry_df = pd.read_csv(Data_Entry_path)
print(BBox_List_df.head()
Data_Entry_df.head()
print(len(BBox_List_df))
print(len(BBox_List_df.iloc[:,0].unique()))
print(len(Data_Entry_df))
print(len(Data_Entry_df.iloc[:,0].unique()))984
880
112120
112120次は「BBox_List_2017.csv」「Data_Entry_2017_v2020.csv」を結合させ、今回使用するデータのみをdata_listに格納していきます。
data_list = BBox_List_df.merge(Data_Entry_df, on='Image Index', how='inner')
data_list = data_list.set_axis(['img_name', 'label', 'bbox_x', 'bbox_y', 'bbox_w', 'bbox_h', 'nan1', 'nan2', 'nan3', 'labels', 'follow_up', 'id', 'age', 'gender', 'view_posi', 'ori_img_w', 'ori_img_h', 'pixel_mm_x', 'pixel_mm_y'], axis=1)
data_list = data_list.drop(['nan1', 'nan2', 'nan3', 'labels', 'follow_up', 'id', 'age', 'gender', 'view_posi', 'pixel_mm_x', 'pixel_mm_y'], axis=1)
data_list.head()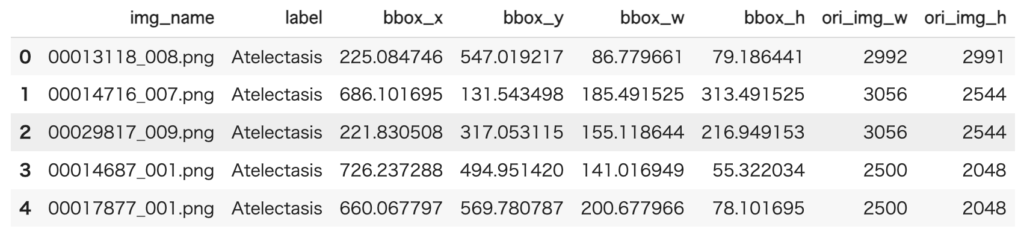
次に、画像ごとにラベルがいくつ付いているかを確認してきます。
下記のように、最大で4つのラベルがついた画像があることが確認できます。
data_list['img_name'].value_counts()00010277_000.png 4
00008814_010.png 3
00018253_059.png 3
00018427_004.png 3
00020482_032.png 3
..
00000756_001.png 1
00008522_032.png 1
00005532_000.png 1
00030206_013.png 1
00026920_000.png 1
Name: img_name, Length: 880, dtype: int642. データの可視化
画像データの表示とともに、正解のラベルとBboxの領域を記載しています。
ラベルは種類ごとに色を変えて表示しています。
今回はgoogle colabを使用しているのですが、google colabはどうも画像の表示や処理が遅いみたいです。
そのため、画像を学習させる際には、png画像から何らかの工夫が必要になってきます。詳しくは後ほど。
import matplotlib.pyplot as plt
import cv2
def image_show(i):
path_dir = '/content/drive/MyDrive/x_ray_chest/images'
#labelごとの色を指定
bbox_color_dict = {'Atelectasis':(255, 0, 0), 'Cardiomegaly':(0, 0, 255), 'Effusion': (50, 205, 50), 'Infiltrate':(255, 255, 0),
'Mass':(255, 0, 255), 'Nodule':(0, 255, 255), 'Pneumonia':(255, 192, 203), 'Pneumothorax':(173, 255, 47)}
text_color_dict = {'Atelectasis':'red', 'Cardiomegaly':'blue', 'Effusion':'limegreen', 'Infiltrate':'y',
'Mass':'m', 'Nodule':'aqua', 'Pneumonia':'pink', 'Pneumothorax':'greenyellow'}
#画像の表示
file_name = data_list['img_name'].unique()[i]
img_path = os.path.join(path_dir, file_name)
img_ori = cv2.imread(img_path)
#データの取り出し
row = data_list['img_name'] == file_name
data = data_list[row]
#bboxごとにループ
for i in range(len(data)):
#bboxの座標を取得
lx = int(data['bbox_x'].iloc[i])
ly = int(data['bbox_y'].iloc[i])
rx = int(data['bbox_x'].iloc[i] + data['bbox_w'].iloc[i])
ry = int(data['bbox_y'].iloc[i] + data['bbox_h'].iloc[i])
#ラベルに沿った色を指定
label_name = data['label'].iloc[i]
bbox_color = bbox_color_dict[label_name]
text_color = text_color_dict[label_name]
#bboxとlabelを表示
cv2.rectangle(img_ori, (lx, ly), (rx, ry), color=(bbox_color), thickness=5)
plt.text(lx, ly-10, label_name, color=text_color)
plt.title(file_name)
plt.imshow(img_ori)
image_show(654)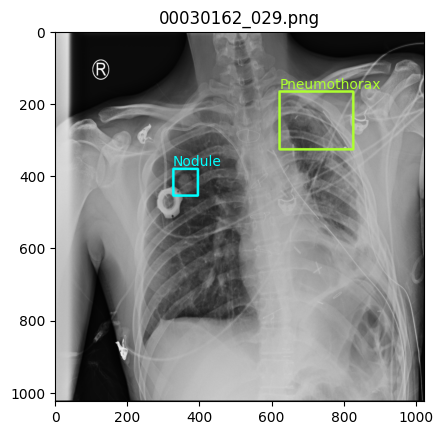
import random
def images_show(row_num, col_num):
random.seed(42)
num = [random.randint(0, 880) for i in range(row_num * col_num)]
path_dir = '/content/drive/MyDrive/x_ray_chest/images'
#labelごとの色を指定
bbox_color_dict = {'Atelectasis':(255, 0, 0), 'Cardiomegaly':(0, 0, 255), 'Effusion': (50, 205, 50), 'Infiltrate':(255, 255, 0),
'Mass':(255, 0, 255), 'Nodule':(0, 255, 255), 'Pneumonia':(255, 192, 203), 'Pneumothorax':(173, 255, 47)}
text_color_dict = {'Atelectasis':'red', 'Cardiomegaly':'blue', 'Effusion':'limegreen', 'Infiltrate':'y',
'Mass':'m', 'Nodule':'aqua', 'Pneumonia':'pink', 'Pneumothorax':'greenyellow'}
fig, axes = plt.subplots(nrows=row_num, ncols=col_num, figsize=(15, 10), subplot_kw=({'xticks':(), 'yticks':()}))
for i, ax in enumerate(axes.flat):
#画像の表示
j = num[i]
file_name = data_list['img_name'].unique()[j]
img_path = os.path.join(path_dir, file_name)
img_ori = cv2.imread(img_path)
#データの取り出し
row = data_list['img_name'] == file_name
data = data_list[row]
#bboxごとにループ
for k in range(len(data)):
#bboxの座標を取得
lx = int(data['bbox_x'].iloc[k])
ly = int(data['bbox_y'].iloc[k])
rx = int(data['bbox_x'].iloc[k] + data['bbox_w'].iloc[k])
ry = int(data['bbox_y'].iloc[k] + data['bbox_h'].iloc[k])
#ラベルに沿った色を指定
label_name = data['label'].iloc[k]
bbox_color = bbox_color_dict[label_name]
text_color = text_color_dict[label_name]
#bboxとlabelを表示
cv2.rectangle(img_ori, (lx, ly), (rx, ry), color=(bbox_color), thickness=5)
ax.text(lx, ly-10, label_name, color=text_color)
ax.set_title(data_list['img_name'].unique()[j], fontsize=10)
ax.imshow(img_ori)
images_show(4, 6)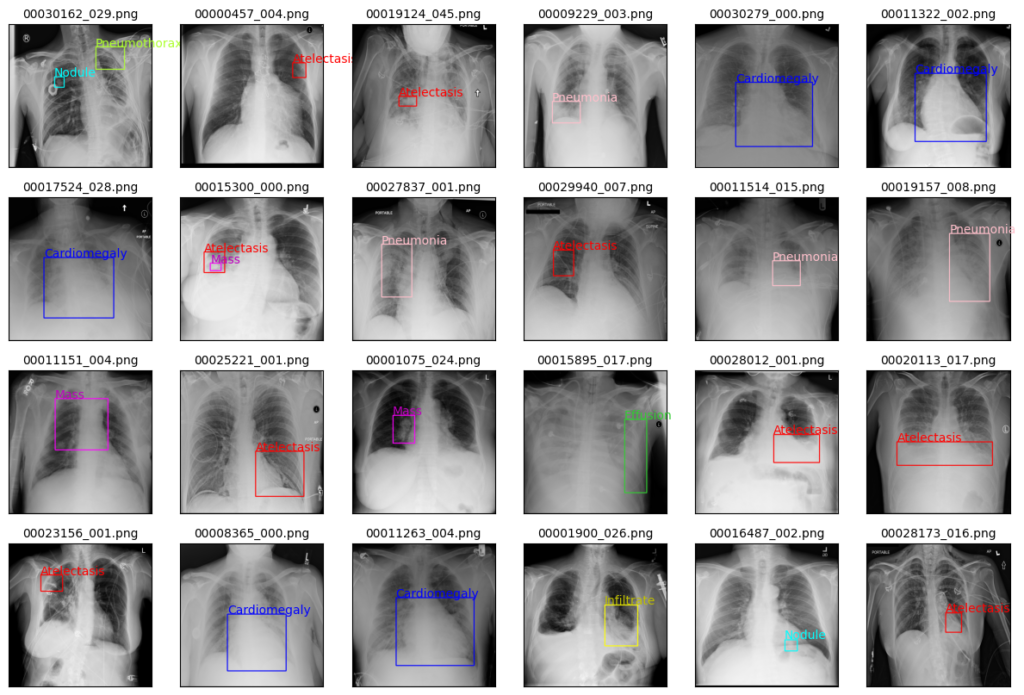
3. データセットの作成
画像データを読み込む前に、画像データを.pngから.hdf5形式に変換していきます。
このようにすることで、google colabから画像データを読み込む処理を高速化しています。
import h5py
import numpy as np
from glob import glob
import os
import cv2
# hdf5ファイルの作成
def hdf5_generate(file_path):
f = h5py.File('file.hdf5', mode='w')
group = f.create_group('/images')
file_list = glob(file_path)
for file in file_list:
arr = cv2.imread(file)
dataset = group.create_dataset(name = os.path.basename(file), shape=arr.shape, dtype=np.uint8)
dataset[...] = arr
f.close()
file_path = '/content/drive/MyDrive/x_ray_chest/images'
hdf5_generate(file_path)次に、画像データ、Bboxの位置座標、ラベルの情報を画像ごとに整理していきます。
import torch
from torch.utils.data import Dataset
import torchvision
from torchvision import datasets
from torchvision import transforms
import h5py
# 画像データをimagesに格納
file_path = '/content/drive/MyDrive/x_ray_chest/file.hdf5'
images = []
with h5py.File(file_path, "r") as f:
group = f["/images"]
for i in range(len(file_name_list)):
file_name = file_name_list[i]
if file_name in group:
dataset = group[file_name]
img_data = np.array(dataset)
img_tensor = transforms.Compose([transforms.ToTensor()])(img_data)
images.append(img_tensor)
# Bbox情報をboxesに格納
boxes = []
for file_name in data_list['img_name'].unique():
box = []
row = data_list['img_name'] == file_name
data = data_list[row]
for i in range(len(data)):
lx = data['bbox_x'].iloc[i]
ly = data['bbox_y'].iloc[i]
rx = data['bbox_x'].iloc[i] + data['bbox_w'].iloc[i]
ry = data['bbox_y'].iloc[i] + data['bbox_h'].iloc[i]
bbox = [lx, ly, rx, ry]
box.append(bbox)
box_tensor = torch.tensor(box, dtype = torch.float)
boxes.append(box_tensor)
# ラベル情報をlabelsに格納
labels = []
label_kind = ['Atelectasis', 'Cardiomegaly', 'Effusion', 'Infiltrate', 'Mass', 'Nodule', 'Pneumonia', 'Pneumothorax']
for file_name in data_list['img_name'].unique():
label = []
row = data_list['img_name'] == file_name
data = data_list[row]
for i in range(len(data)):
label_name = data['label'].iloc[i]
label_index = label_kind.index(label_name)
label.append(label_index)
label_tensor = torch.tensor(label, dtype = torch.int64)
labels.append(label_tensor)
print(len(images))
print(len(boxes))
print(len(labels))880
880
880datasetに辞書型でそれぞれのデータをまとめていきます。
dataset = []
for i in range(len(images)):
data = (images[i], {'boxes':boxes[i], 'labels':labels[i]}, data_list['img_name'].unique()[i])
dataset.append(data)train, val, testに使用するデータを分割していきます。
割合はtrain:val:test=8:1:1程度にしています。
また、バッチサイズですがpytorchのfaster-r-cnnモデルでは、入力データのサイズを合わせる必要がありました。
そのため、今回のように一つの画像中に含まれるラベル数が異なる場合には、バッチサイズを1にして入力する必要があります。
その他の方法だと、データセットを作成する際に、ラベルごとにデータを整理し、合計984個のデータを分割する方法が考えられます。
train, val, test = torch.utils.data.random_split(dataset=dataset, lengths=[736, 72, 72], generator=torch.Generator().manual_seed(42))
train_loader = torch.utils.data.DataLoader(train, batch_size = 1, shuffle=True)
val_loader = torch.utils.data.DataLoader(val, batch_size = 1, shuffle=False)
test_loader = torch.utils.data.DataLoader(test, batch_size = 1, shuffle=False)ここではtrain, val, testで分割したファイル名をテキストファイルで出力しています。
train_list = []
val_list = []
test_list = []
[train_list.append(data[2]) for data in train_loader]
[val_list.append(data[2]) for data in val_loader]
[test_list.append(data[2]) for data in test_loader]
train_txt_path = os.path.join(train_folder_path, 'train_list.txt')
val_txt_path = os.path.join(train_folder_path, 'val_list.txt')
test_txt_path = os.path.join(train_folder_path, 'test_list.txt')
with open(train_txt_path, 'w') as f:
for item in train_list:
f.write(str(item) + '\n')
with open(val_txt_path, 'w') as f:
for item in val_list:
f.write(str(item) + '\n')
with open(test_txt_path, 'w') as f:
for item in test_list:
f.write(str(item) + '\n')
4. モデルの作成
今回はpytorchで使用できるFaster-R-CNNモデルを使用していきます。
pretrainedをTrueにすることで転移学習を行なっています。
また、classの数を変更し、予測の構造の部分に変更の値を返しています。
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
num_classes = (len(label_kind)) + 1
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
model/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=FasterRCNN_ResNet50_FPN_Weights.COCO_V1`. You can also use `weights=FasterRCNN_ResNet50_FPN_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
Downloading: "https://download.pytorch.org/models/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth" to /root/.cache/torch/hub/checkpoints/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
100%|██████████| 160M/160M [00:00<00:00, 176MB/s]
FasterRCNN(
(transform): GeneralizedRCNNTransform(
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
Resize(min_size=(800,), max_size=1333, mode='bilinear')
)
(backbone): BackboneWithFPN(
(body): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d(256, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(512, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(1024, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(2048, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
)
)
(fpn): FeaturePyramidNetwork(
(inner_blocks): ModuleList(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): Conv2dNormActivation(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): Conv2dNormActivation(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
)
(3): Conv2dNormActivation(
(0): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(layer_blocks): ModuleList(
(0-3): 4 x Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(extra_blocks): LastLevelMaxPool()
)
)
(rpn): RegionProposalNetwork(
(anchor_generator): AnchorGenerator()
(head): RPNHead(
(conv): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
)
)
(cls_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(bbox_pred): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
)
(roi_heads): RoIHeads(
(box_roi_pool): MultiScaleRoIAlign(featmap_names=['0', '1', '2', '3'], output_size=(7, 7), sampling_ratio=2)
(box_head): TwoMLPHead(
(fc6): Linear(in_features=12544, out_features=1024, bias=True)
(fc7): Linear(in_features=1024, out_features=1024, bias=True)
)
(box_predictor): FastRCNNPredictor(
(cls_score): Linear(in_features=1024, out_features=9, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=36, bias=True)
)
)
)今回は学習済みモデルを使用しましたが、自身で色々とカスタマイズしたい方は、pytorchのライブラリを一度ローカルPC上にダウンロードしてコードをいじるのがオススメです。
その後、google colabにアップロードし、sys.path.appendでライブラリのパスを追加すると自由にカスタマイズしたライブラリが使用できます。
5. 学習
今回はエポック数200で学習を行っていきます。
学習をうまく進めるコツとして、オプティマイザおよび学習率を調整しました。
オプティマイザはSGDやNAdamなど色々ありますが、無難なイメージのあるAdamを使用しています。
有名なオプティマイザのSGDは、学習率を調整しないとAdamのようにうまく学習できないイメージが個人的にあります。
学習率は小さめにすることで、lossが下がり切るまで時間はかかりますが、よりlossの値が小さく落ち着くように設定しました。
import csv
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.Adam(params, lr=0.0001)
epochs = 200
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
loss_train_list=[]
loss_val_list = []
loss_outdir = os.path.join(train_folder_path, 'train_loss.csv')
with open(loss_outdir, 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(['epoch', 'train loss', 'val loss'])
for epoch in range(epochs):
model.train()
loss_train_epo=[]
for batch in train_loader:
images, targets, name = batch
images = list(image.to(device) for image in images)
boxes = list(box.to(device) for box in targets['boxes'])
labels = list(label.to(device) for label in targets['labels'])
targets = list([{'boxes':boxes[i], 'labels':labels[i]} for i in range(len(images))])
loss_dict = model(images, targets)
loss = sum(loss for loss in loss_dict.values())
loss_value = loss.item()
loss_train_epo.append(loss_value)
#パラメータを更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
#Epochごとのlossの保存
loss_train_ave = sum(loss_train_epo)/len(loss_train_epo)
loss_train_list.append(loss_train_ave)
weight_num = str(epoch+1).zfill(4)
weight_name = f'weight_{weight_num}.pt'
torch.save(model.state_dict(), os.path.join(weight_folder_path, weight_name))
with torch.no_grad():
model.eval()
loss_val_epo=[]
for batch in val_loader:
images, targets, name = batch
images = list(image.to(device) for image in images)
boxes = list(box.to(device) for box in targets['boxes'])
labels = list(label.to(device) for label in targets['labels'])
targets = list([{'boxes':boxes[i], 'labels':labels[i]} for i in range(len(images))])
loss_dict = model(images, targets)
score_list = []
for i in range(len(loss_dict)):
score = loss_dict[i]['scores'].sum()
score_value = score.item()
score_list.append(score_value)
#lossの保存
score_ave = sum(score_list)/len(score_list)
loss_val_epo.append(score_ave)
#Epochごとのlossの保存
loss_val_ave = sum(loss_val_epo)/len(loss_val_epo)
loss_val_list.append(loss_val_ave)
print(f"epoch: {epoch+1}, loss: {np.mean(loss_train_epo)}, val loss: {loss_val_ave}")
with open(loss_outdir, 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow([epoch+1, loss_train_ave, loss_val_ave])
epoch: 1, loss: 0.24110975912923965, val loss: 0.3246306985513204
epoch: 2, loss: 0.2282996491336709, val loss: 1.4351968351337645
epoch: 3, loss: 0.22264097455089263, val loss: 1.4306978616449568
epoch: 4, loss: 0.20749079919946584, val loss: 5.093314859602186
epoch: 5, loss: 0.20251873579463395, val loss: 2.666413033174144
epoch: 6, loss: 0.19240049850296878, val loss: 3.341125517669651
epoch: 7, loss: 0.1835352772867064, val loss: 2.689231221874555
epoch: 8, loss: 0.17658887369401308, val loss: 4.5536469121774035
epoch: 9, loss: 0.1688745028918872, val loss: 2.3997186314728527
epoch: 10, loss: 0.1469138625417026, val loss: 1.6564890493949254
epoch: 11, loss: 0.13697218944688086, val loss: 1.600402367197805
epoch: 12, loss: 0.12709340538181688, val loss: 5.514973554346296
epoch: 13, loss: 0.11845372894173994, val loss: 1.5726642373742328
epoch: 14, loss: 0.10922473976224074, val loss: 2.916120736135377
epoch: 15, loss: 0.09690021435475817, val loss: 0.9303635937265224
epoch: 16, loss: 0.09325711836288025, val loss: 2.534821828827262
epoch: 17, loss: 0.08580996685399757, val loss: 0.8161833409944342
epoch: 18, loss: 0.08081575220144853, val loss: 1.0927526873225968
epoch: 19, loss: 0.08133552688330224, val loss: 1.3887748159468174
epoch: 20, loss: 0.0727521351126716, val loss: 1.0132182172189157
epoch: 21, loss: 0.07121367414741975, val loss: 0.6771124113971988
epoch: 22, loss: 0.06907023071147231, val loss: 0.8857596593184603
epoch: 23, loss: 0.06628901709400056, val loss: 0.9108521235692832
epoch: 24, loss: 0.06673509317007974, val loss: 0.7442856341496937
epoch: 25, loss: 0.062146506343829656, val loss: 0.6246414736637639
epoch: 26, loss: 0.061015041457029955, val loss: 0.8104739433878826
epoch: 27, loss: 0.05744573669898787, val loss: 0.6706496070449551
epoch: 28, loss: 0.05474606130531395, val loss: 1.1524773749212425
epoch: 29, loss: 0.055251803001145, val loss: 0.6280674000995027
epoch: 30, loss: 0.05273347761818593, val loss: 0.5754670017502375
epoch: 31, loss: 0.050008386024669366, val loss: 0.32528595057212645
epoch: 32, loss: 0.04966567055548101, val loss: 0.33050697633168763
epoch: 33, loss: 0.04912358499397036, val loss: 0.6783891286080083
epoch: 34, loss: 0.04859020433116751, val loss: 0.6152269225050178
epoch: 35, loss: 0.04452142692258823, val loss: 0.43346481651274693
epoch: 36, loss: 0.04439374794684108, val loss: 0.5061396388337016
epoch: 37, loss: 0.04699440649489153, val loss: 0.25037881680246854
epoch: 38, loss: 0.04393274197362822, val loss: 0.19273884480612147
epoch: 39, loss: 0.0412014624346383, val loss: 0.33793715734241736
epoch: 40, loss: 0.042301838821162084, val loss: 0.37770448345690966
epoch: 41, loss: 0.03826545933112436, val loss: 0.3075255771788458
epoch: 42, loss: 0.03726111880393754, val loss: 0.3168445967344774
epoch: 43, loss: 0.040553005828631125, val loss: 0.289791036500699
epoch: 44, loss: 0.03873104128914075, val loss: 0.15397230784098306
epoch: 45, loss: 0.03735997831830426, val loss: 0.3136507644214564
epoch: 46, loss: 0.040122704197647574, val loss: 0.16717039897210068
epoch: 47, loss: 0.036537003315763046, val loss: 0.1613647932600644
epoch: 48, loss: 0.033273397550542344, val loss: 0.9169100125113295
epoch: 49, loss: 0.032753672763370247, val loss: 0.1807647309679952
epoch: 50, loss: 0.03304693002030984, val loss: 0.26329267945968443
epoch: 51, loss: 0.03421700729768418, val loss: 0.22143234483276805
epoch: 52, loss: 0.03436298223811679, val loss: 0.17814058189590773
epoch: 53, loss: 0.03525825669009425, val loss: 0.1409107974419991
epoch: 54, loss: 0.03350234282104635, val loss: 0.11430964044605692
epoch: 55, loss: 0.03423632765061089, val loss: 0.10250198634134398
epoch: 56, loss: 0.03222063158434297, val loss: 0.1298580646721853
epoch: 57, loss: 0.030284645334631932, val loss: 0.18020476235283744
epoch: 58, loss: 0.030352800964692506, val loss: 0.1549433045503166
epoch: 59, loss: 0.030562790613400823, val loss: 0.2312512820483082
epoch: 60, loss: 0.030917203308095137, val loss: 0.23355705296206805
epoch: 61, loss: 0.03158575625170472, val loss: 0.19695975269294447
epoch: 62, loss: 0.030637340262629827, val loss: 0.4018483566534188
epoch: 63, loss: 0.03038886107491556, val loss: 0.1631715577095747
epoch: 64, loss: 0.029974979020686948, val loss: 0.11120111500430438
epoch: 65, loss: 0.030613049891154213, val loss: 0.17864933537526262
epoch: 66, loss: 0.03159083963053332, val loss: 0.139477732591331
epoch: 67, loss: 0.03271760230856434, val loss: 0.1599722879214419
epoch: 68, loss: 0.029625480446117326, val loss: 0.3108530937073131
epoch: 69, loss: 0.02876559113926068, val loss: 0.15876602800562978
epoch: 70, loss: 0.030224516301359472, val loss: 0.10369957486788432
epoch: 71, loss: 0.028860015232235917, val loss: 0.3006380044130815
epoch: 72, loss: 0.028128108247924305, val loss: 0.20257677784603503
epoch: 73, loss: 0.025224404149293663, val loss: 0.12164105402512683
epoch: 74, loss: 0.02306718988983369, val loss: 0.08393369884126717
epoch: 75, loss: 0.023504642101680354, val loss: 0.222478655529105
epoch: 76, loss: 0.026592813241894993, val loss: 0.23118829049376977
epoch: 77, loss: 0.027799449206292553, val loss: 0.12991651333868504
epoch: 78, loss: 0.0246156811292325, val loss: 0.12436481911896004
epoch: 79, loss: 0.02376350378300112, val loss: 0.16421864135190845
epoch: 80, loss: 0.02365450924107988, val loss: 0.47107588758485186
epoch: 81, loss: 0.024729895744416273, val loss: 0.1490647716758152
epoch: 82, loss: 0.023687794335501167, val loss: 0.1587101083455814
epoch: 83, loss: 0.023237756310248624, val loss: 0.099386107073062
epoch: 84, loss: 0.021971292128653105, val loss: 0.20810616456179154
epoch: 85, loss: 0.02278891849900704, val loss: 0.12188714313217336
epoch: 86, loss: 0.02504808868678518, val loss: 0.10159987966633505
epoch: 87, loss: 0.02462780592839448, val loss: 0.07811070802725023
epoch: 88, loss: 0.023621539326274178, val loss: 0.21318252560579115
epoch: 89, loss: 0.023184740303191655, val loss: 0.15177055360335442
epoch: 90, loss: 0.02191986730014892, val loss: 0.16432732861075136
epoch: 91, loss: 0.024063879810959723, val loss: 0.1003557765442464
epoch: 92, loss: 0.023978719674529282, val loss: 0.2154051615960068
epoch: 93, loss: 0.023383827642686338, val loss: 0.12893925441635978
epoch: 94, loss: 0.023065722899010998, val loss: 0.13664892936746278
epoch: 95, loss: 0.023316614966456258, val loss: 0.17552660571204293
epoch: 96, loss: 0.023419570080032707, val loss: 0.2663915485350622
epoch: 97, loss: 0.021505099566134642, val loss: 0.06453627999871969
epoch: 98, loss: 0.019993429047051748, val loss: 0.1580528343717257
epoch: 99, loss: 0.020646440756219974, val loss: 0.09689174654583137
epoch: 100, loss: 0.020709944858624665, val loss: 0.11231084085173076
・・・
・・・train lossおよびval lossを確認していきます。
import os
import pandas as pd
loss_outdir = os.path.join(train_folder_path, 'train_loss.csv')
loss_df = pd.read_csv(loss_outdir)
print(loss_df)
val_loss_min = min(loss_df['val loss'])
min_epoch_row = loss_df[loss_df['val loss'] == val_loss_min].iloc[0]
min_epoch = min_epoch_row['epoch']
print(f'val_loss_min: {val_loss_min}, epoch: {min_epoch}') epoch train loss val loss
0 1 0.241110 0.324631
1 2 0.228300 1.435197
2 3 0.222641 1.430698
3 4 0.207491 5.093315
4 5 0.202519 2.666413
.. ... ... ...
195 196 0.013474 0.029489
196 197 0.013110 0.034138
197 198 0.013515 0.063616
198 199 0.015549 0.088352
199 200 0.012575 0.067777
[200 rows x 3 columns]
val_loss_min: 0.008613680385881, epoch: 182.0val lossが最も小さくなったのはepoch数が182の時で、0.0086136となっています。
次はepoch数ごとのlossの変化を見ていきましょう。
from matplotlib import pyplot as plt
import numpy as np
# 全体設定
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['xtick.major.width'] = 1.2
plt.rcParams['ytick.major.width'] = 1.2
plt.rcParams['font.size'] = 12
plt.rcParams['axes.linewidth'] = 1.2
plt.rcParams['axes.grid']=True
plt.rcParams['grid.linestyle']='--'
plt.rcParams['grid.linewidth'] = 0.3
plt.rcParams["legend.markerscale"] = 2
plt.rcParams["legend.fancybox"] = False
plt.rcParams["legend.framealpha"] = 1
plt.rcParams["legend.edgecolor"] = 'black'
fig = plt.figure()
ax1 = fig.subplots()
ax2 = ax1.twinx()
ax1.plot(loss_df['epoch'], loss_df['train loss'], color="blue", label="train loss")
ax2.plot(loss_df['epoch'], loss_df['val loss'], c="r", label="val loss")
ax1.set_xlim(0, 200)
ax1.set_ylim(0, 0.4)
ax1.set_xlabel('epochs')
ax1.set_ylabel('train loss')
ax2.set_xlim(0, 200)
ax2.set_ylim(0, 4.0)
ax2.set_xlabel('epochs')
ax2.set_ylabel('val loss')
plt.grid(color = "gray", linestyle="dotted")
plt.title("train loss, val loss vs epochs")
h1, l1 = ax1.get_legend_handles_labels()
h2, l2 = ax2.get_legend_handles_labels()
ax1.legend(h1 + h2, l1 + l2)
plt.show()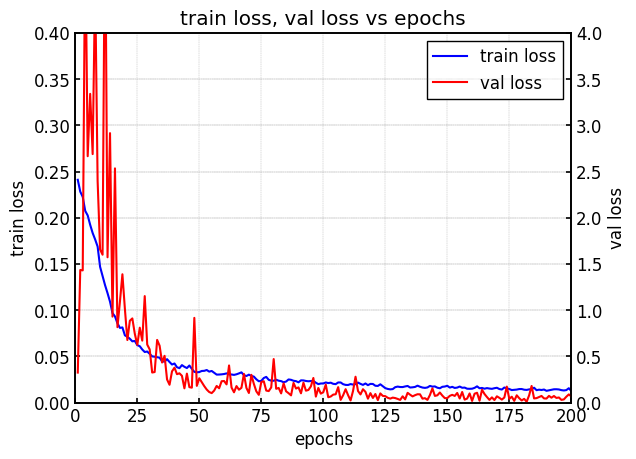
学習が進むにつれてtrain lossおよびval lossが低下していることが確認できます。
lossの値からは過学習も見られず、うまく学習できていることが確認できました。
次は、最もval lossの値が小さくなったepoch数:182のモデルを使用してtestデータの予測を行っていきます。

コメント