

今回紹介するのはアメリカにあるNIH臨床センターが提供している胸部X線データセットです。
このデータセットは30,000以上の患者に対して、胸部X線検査を実施したデータとなっています。
さて、今回紹介する胸部X線レントゲン画像の読影および診断は、放射線科医にとっては比較的単純な作業と言われています。
しかし、一般的には専門の知識や注意深い観察を必要とする複雑な作業であり、医師による診断の確認や、診断の見落としの防止を目的として深層学習モデルを使用した画像処理が提案されている。
また、この一連の作業を自動化する際には複雑な問題が存在する。
特に、疾患の種類によっては疾患の特徴が掴みづらいものも存在し、AIにその特徴を学習されることは非常に困難である。
今回は提供された胸部X線レントゲン画像の中身について紹介しながら、機械学習のデータセットとして使用する際の注意点も併せて解説していきたい。
データ活用の目的
・医師による診断の確認および見落としの防止
・症状の早期発見
・読影および診断の自動化による医療従事者の負担軽減
・放射線科医の少ない地域・発展途上国の患者に対する医療提供
・医学教育における豊富なデータの提供
データの中身について
データの中身は以下のようになっています。
ここで重要なるのが、「images」「Data_Entry_2017_v2020.csv」「BBox_List_2017.csv」の三つのフォルダまたはファイルです。
それぞれ詳しく説明していきます。
「images」フォルダ
「images」フォルダには以下のように「images_001.tar.gz」〜「images_012.tar.gz」にそれぞれ10,000枚程度の画像が含まれています。
ただし、各フォルダに対して疾患のラベルがついた画像は一部分となっています。
「images」フォルダ全体には100,000枚程含まれているのですが、ラベルやBBoxの情報を含む画像は900枚程度になっています。
次に、「BBox_List_2017.csv」と「Data_Entry_2017_v2020.csv」について説明します。
BBox_List_2017.csv
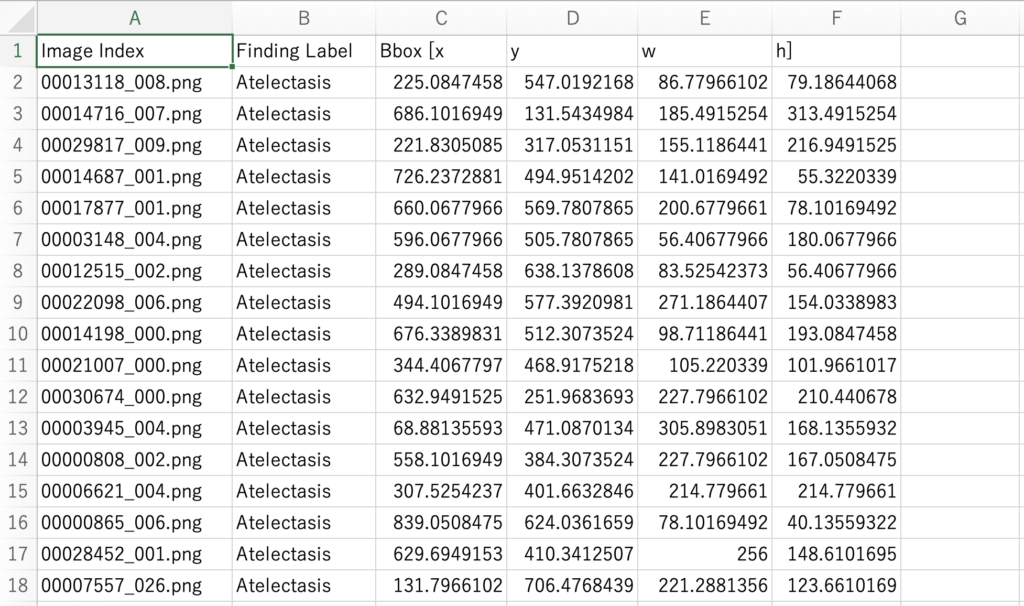
BBox_List_2017.csvは 「Image Index」「Finding Label」「Bbox[x, y, w, h]」で形成されています。
Image Index:画像ファイル名
Finding Label:正解ラベル名(疾患名)
Bbox[x, y, w, h]:正解BBoxの位置情報(左上のX座標、左上のY座標、幅、高さ)
全部で984行のデータから形成されており、984個の疾患ラベルとBboxの情報が記載されています。
ここで注意が必要なのが、ExcelのA列の画像ファイル名において、同様のファイル名が複数存在する点です。
これは一つの画像に対して複数の疾患が存在する場合があるからです。
ある疾患が他の疾患を誘発する可能性もありますし、ある疾患の要因が他の疾患を引き起こす要因となる可能性もあります。
そのため、深層学習の学習時にはどのようにデータを処理させるかにも注意が必要です。
Data_Entry_2017_v2020.csv
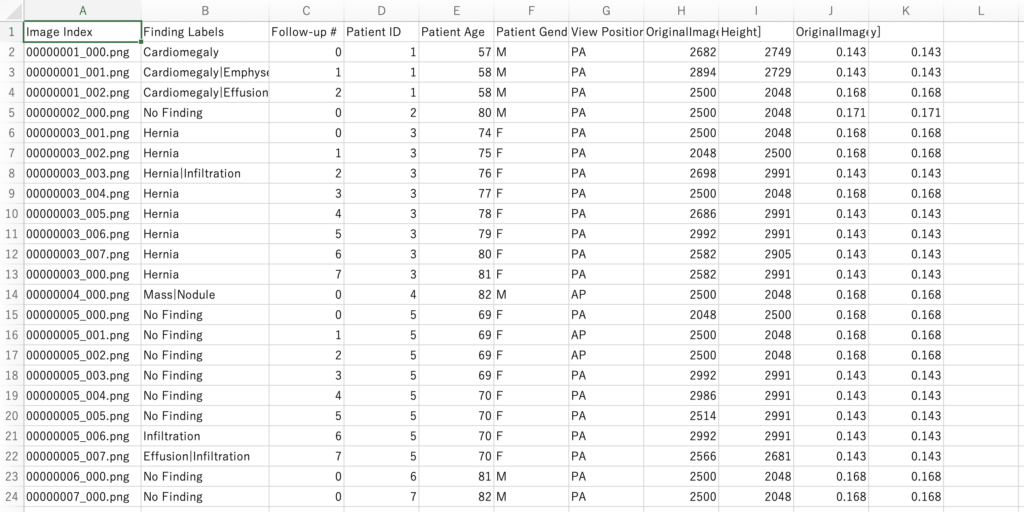
Data_Entry_2017_v2020.csvは 「Image Index」「Finding Label」「Follow-up」「Patient ID」「Patient Age」「Patient Gender」「View Position」「OriginalImage[Width, Height]」「OriginalImagePixelSpacing[x, y]」で形成されています。
Image Index:画像ファイル名
Finding Label:正解ラベル名(疾患名)
Follow-up:途中経過の段階(0, 1, 2, 3….)
Patient ID:患者の識別ID
Patient Age:年齢
Patient Gender:性別(M, F)
View Position:X線の照射方向(AP, PA)
OriginalImage[Width, Height]:元画像の大きさ(幅、高さ)
OriginalImagePixelSpacing[x, y]:画素(ピクセル)の間隔
多くの情報がありますが、中でもわかりにくい項目を説明していきます。
まず、Follow-upですが、一人の患者に対して複数の途中経過のデータが存在するため、途中経過の段階を0,1,2..などの数字で表しています。
次にView Positionですが、これはX線レントゲン画像を撮る際の、X線の照射方向を表しています。
APは胸部から背部にかけてX線を照射した場合、PAは背部から胸部にかけてX線を照射した場合です。
OriginalImageはデータセットとして提供される前の医療の現場にて、撮影された元画像のサイズを表しています。
OriginalImagePixelSpacingは一つ一つの画素の間隔を表しており、OriginalImagePixelSpacingの値が小さいほど画素が密集しているため、画質が良くなります。
全部で112,120行のデータから形成されており、全ての画像に対してラベルの有無や種類、その他の情報が記載されています。
先ほど紹介したBBox_List_2017.csvと異なり、Bboxの情報を含んでおらず、物体検出などのデータとして使用する際はBBox_List_2017.csvのデータとmergeさせて使用してください。
そのため、物体検出のデータセットしては、BBox_List_2017.csv内の984個のデータしか使用できません。
データの可視化
実際に上記のフォルダおよびファイルからデータを取得し、データを可視化した結果を以下に示す。
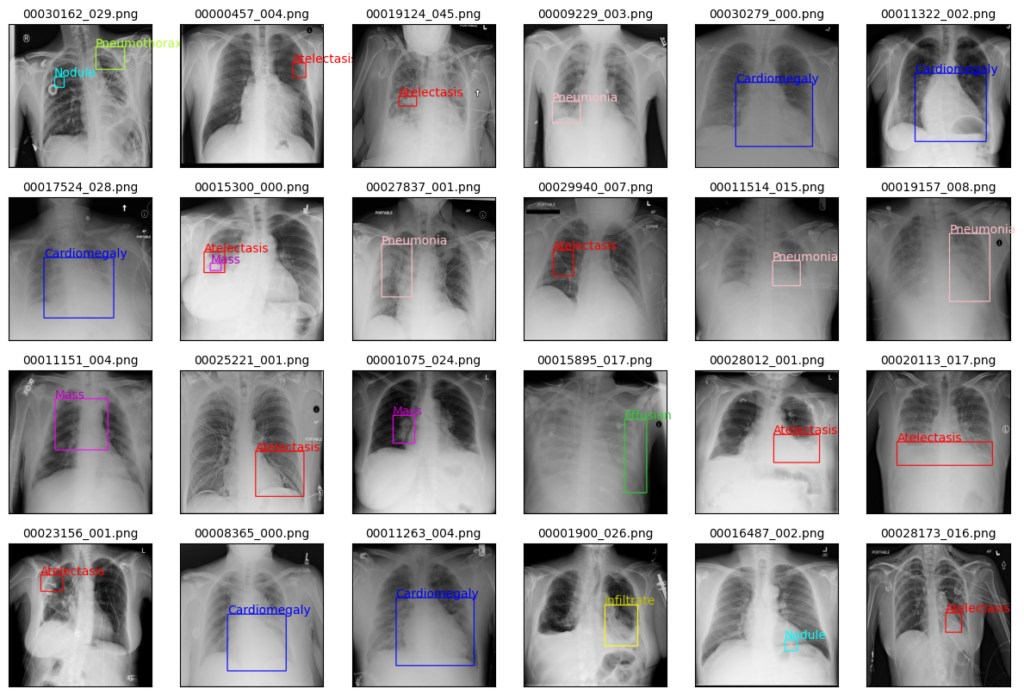
一見してわかりやすい疾患から、よく観察してもわからない疾患まで、さまざまなデータが存在している。
個人的な意見ですと、Cardiomegaly(心肥大)は特徴がわかりやすいので、学習の精度も高くなりそうですね。
データの問題点
ラベルの偏り
まず各疾患の種類およびラベルの数を確認します。
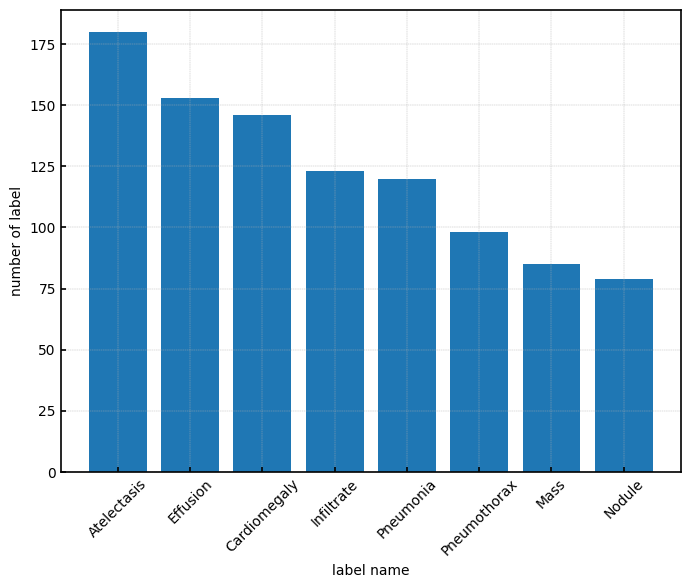
上記のように、疾患によってデータ数が異なることが見て取れます。
これらのデータを使用して学習を行う際、データ数の多い疾患が繰り返し学習されることで、目的に沿ったモデルが得られない可能性があります。
データ不足
上記で示したように、各ラベルのデータ数は機会学習を行うにはやや少なくなっています。
また、train, val, testの過程などにデータを分割するとさらにデータ数が減るので、要注意です。
捉えづらい疾患の特徴
実際の画像データおよび疾患箇所をマークした例を下記に示す。
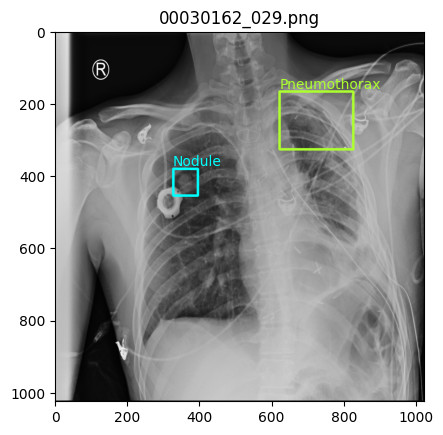
上記の画像を見てもわかるように、特定の疾患は背景のレントゲン画像と識別するのが困難であり、特徴そのものがかなり見えづらくなっています。
深層学習を行う際、こういった特徴がうまく学習されない可能性も存在する。例えば、実施の疾患箇所を背景として提案されるなどの事例が考えられる。
観察条件の違い
先ほどData_Entry_2017_v2020.csvにて、データが取られた際の諸条件について説明しました。
今回、これらの画像データを物体検出モデルに使用すると仮定した場合、以下の諸条件が学習に影響を及ぼす可能性があります。
- Patient Age:年齢
- Patient Gender:性別(M, F)
- View Position:X線の照射方向(AP, PA)
どれもレントゲン画像の見え方に影響を及ぼす可能性があり、異なる年齢・性別・X線照射方向を含んだデータを混在させた状態で用いるべきか検討が必要です。
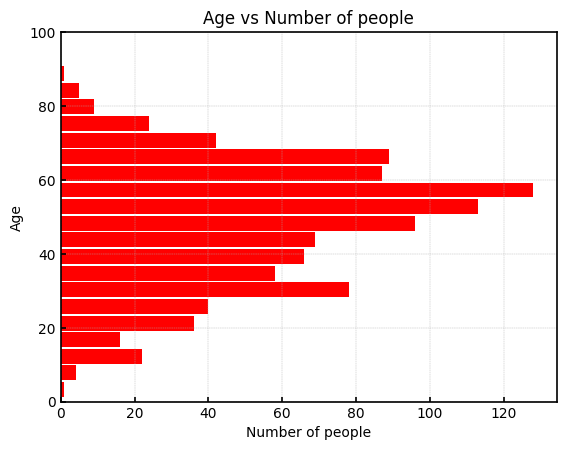
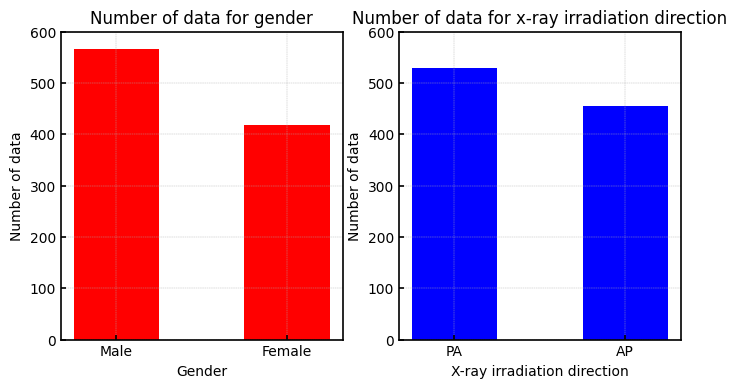
年齢・性別・X線照射方向によるデータ数の分布を上図に示します。
年齢に関しては、1歳から91歳までデータが存在し、体の構造はほとんど変わらないと考えられます。
一方で、1歳などの極端に年齢が低い場合には、体が十分に成長していないことも考えられるので、データを確認しながら取捨選択するといいかもしれません。
また、性別・X線の照射方向によってデータ数に大きな差はなく、これらの差が画像の見え方にどれだけ影響があるかを加味してデータを選別する必要があります。
このように多くの懸念点が存在しますが、今回はデータ数が少ないため、これらの項目を加味しないのも一つの選択だと思われます。
活用例
物体検出モデル(Faster-R-CNN)

引用元
paper & article
- Wang X, Peng Y, Lu L, Lu Z, Bagheri M, Summers RM. ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. IEEE CVPR 2017, http://openaccess.thecvf.com/content_cvpr_2017/papers/Wang_ChestX-ray8_Hospital-Scale_Chest_CVPR_2017_paper.pdf
- Kaggle: https://www.kaggle.com/datasets/nih-chest-xrays/data/data
images data
- Images are available via Box: https://nihcc.app.box.com/v/ChestXray-NIHCC
other
- About the NIH Clinical Center: The NIH Clinical Center is the clinical research hospital for the National Institutes of Health. Through clinical research, clinician-investigators translate laboratory discoveries into better treatments, therapies and interventions to improve the nation’s health. More information: https://clinicalcenter.nih.gov.
- News Releases: NIH Clinical Center provides one of the largest publicly available chest x-ray datasets to scientific community: https://www.nih.gov/news-events/news-releases/nih-clinical-center-provides-one-largest-publicly-available-chest-x-ray-datasets-scientific-community
コメント