

今回は前回に続き、学習させたモデルを使用してtestデータの予測を行っていきます。
今回はmodel_pathで指定しているように、エポック数30のモデルを使用しています。
その後、エポック数を変化させながら、予測結果がどのように変化するかを確認していきます。
testデータの予測結果(epoch=30のモデル)
エポック数30のモデルを使用して予測を行います。
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
model_path = '/content/drive/MyDrive/x_ray_chest/results/faster_r_cnn/v1/weight/weight_0030.pt'
model.load_state_dict(torch.load(model_path))
test_results = []
model.eval()
with torch.no_grad():
for batch in test_loader:
image, target, name = batch
image = image.to(device)
predictions = model(image)
#print(predictions)
image = image.cpu()
truth_boxes = target['boxes'][0].cpu()
truth_labels = target['labels'][0].cpu()
predict_boxes = predictions[0]["boxes"].cpu()
predict_labels = predictions[0]["labels"].cpu()
predict_scores = predictions[0]["scores"].cpu()
dict_info = {'image':image, 'truth_boxes':truth_boxes, 'truth_labels':truth_labels, 'file_name':name,
'predict_boxes':predict_boxes, 'predict_labels':predict_labels, 'scores':predict_scores}
test_results.append(dict_info)
print(test_results[66])
{'image': tensor([[[[0.0078, 0.0118, 0.0118, ..., 0.0235, 0.0275, 0.0118],
[0.0157, 0.0275, 0.0275, ..., 0.0471, 0.0549, 0.0275],
[0.0157, 0.0275, 0.0275, ..., 0.0471, 0.0471, 0.0314],
...,
[0.0902, 0.1882, 0.2118, ..., 0.0549, 0.0667, 0.0353],
[0.0902, 0.2000, 0.2275, ..., 0.0588, 0.0706, 0.0353],
[0.0431, 0.0980, 0.1020, ..., 0.0275, 0.0314, 0.0157]],
[[0.0078, 0.0118, 0.0118, ..., 0.0235, 0.0275, 0.0118],
[0.0157, 0.0275, 0.0275, ..., 0.0471, 0.0549, 0.0275],
[0.0157, 0.0275, 0.0275, ..., 0.0471, 0.0471, 0.0314],
...,
[0.0902, 0.1882, 0.2118, ..., 0.0549, 0.0667, 0.0353],
[0.0902, 0.2000, 0.2275, ..., 0.0588, 0.0706, 0.0353],
[0.0431, 0.0980, 0.1020, ..., 0.0275, 0.0314, 0.0157]],
[[0.0078, 0.0118, 0.0118, ..., 0.0235, 0.0275, 0.0118],
[0.0157, 0.0275, 0.0275, ..., 0.0471, 0.0549, 0.0275],
[0.0157, 0.0275, 0.0275, ..., 0.0471, 0.0471, 0.0314],
...,
[0.0902, 0.1882, 0.2118, ..., 0.0549, 0.0667, 0.0353],
[0.0902, 0.2000, 0.2275, ..., 0.0588, 0.0706, 0.0353],
[0.0431, 0.0980, 0.1020, ..., 0.0275, 0.0314, 0.0157]]]]), 'truth_boxes': tensor([[331.3898, 487.8644, 839.0508, 836.0678]]), 'truth_labels': tensor([1]), 'file_name': ('00005066_005.png',), 'predict_boxes': tensor([[308.4593, 502.1796, 852.2029, 831.9159],
[133.1272, 196.0398, 332.7476, 830.9913],
[189.2764, 147.7972, 430.6967, 479.0348],
[ 80.8291, 495.3941, 322.3184, 807.7531],
[124.7072, 563.1616, 304.1560, 764.6153],
[205.2015, 184.5955, 331.6555, 478.4204]]), 'predict_labels': tensor([1, 2, 7, 2, 2, 2]), 'scores': tensor([0.8988, 0.1307, 0.1194, 0.0688, 0.0516, 0.0506])}上記のように、正解のデータと予測のデータをまとめて格納しています。
scoresはconfident scoreと呼ばれるもので、モデルがどのくらい自信を持って予測の値を計算しているかを示しています。
次に、計算した予測データを元に、予測結果の表示および結果画像の保存を行います。
import random
def rand_num(start_num, fin_num, rand_num):
ns = []
while len(ns) < rand_num:
n = random.randint(start_num, fin_num)
if not n in ns:
ns.append(n)
return ns
def images_show(row_num, col_num):
random.seed(42)
num = rand_num(0, len(test_results)-1, row_num * col_num)
print(num)
fig, axes = plt.subplots(nrows=row_num, ncols=col_num, figsize=(12, 20), subplot_kw=({'xticks':(), 'yticks':()}))
for i, ax in enumerate(axes.flat):
j = num[i]
test_results_dict = test_results[j]
#元画像の設定
img = (test_results_dict['image'][0] * 255).to(torch.uint8)
img_ori = np.transpose(img.cpu().numpy(), (1, 2, 0))
img_ori = cv2.cvtColor(img_ori, cv2.COLOR_RGB2BGR)
#正解labelごとにループ
for i in range(len(test_results_dict['truth_labels'])):
#正解bbox,labelの色を指定
t_label_index = test_results_dict['truth_labels'][i]
t_label_name = label_kind[int(t_label_index)]
#truth_bboxとtruth_labelを表示
cv2.rectangle(img_ori,
(int(test_results_dict['truth_boxes'][i][0]), int(test_results_dict['truth_boxes'][i][1])),
(int(test_results_dict['truth_boxes'][i][2]), int(test_results_dict['truth_boxes'][i][3])),
color=(0, 255, 0),
thickness=5
)
ax.text(int(test_results_dict['truth_boxes'][i][0]), int(test_results_dict['truth_boxes'][i][1]-15), t_label_name, color='limegreen')
#予測labelごとにループ
for i in range(len(test_results_dict['predict_labels'])):
#予測bbox,labelの色を指定
p_label_index = test_results_dict['predict_labels'][i]
p_label_name = label_kind[int(p_label_index)]
#predict_bboxとpredict_labelを表示
cv2.rectangle(img_ori,
(int(test_results_dict['predict_boxes'][i][0]), int(test_results_dict['predict_boxes'][i][1])),
(int(test_results_dict['predict_boxes'][i][2]), int(test_results_dict['predict_boxes'][i][3])),
color=(255, 0, 0),
thickness=5
)
ax.text(int(test_results_dict['predict_boxes'][i][0]), int(test_results_dict['predict_boxes'][i][1]-15), p_label_name, color='red')
#凡例の設定
cv2.rectangle(img_ori, (10, 10), (280, 120), color=(255, 255, 255), thickness=cv2.FILLED)
cv2.line(img_ori, (30, 40), (70, 40), color=(0, 255, 0), thickness=6, lineType=cv2.LINE_8, shift=0)
cv2.line(img_ori, (30, 90), (70, 90), color=(255, 0, 0), thickness=6, lineType=cv2.LINE_8, shift=0)
ax.text(100, 50, 'truth', color='limegreen', fontsize='x-small')
ax.text(100, 100, 'predict', color='red', fontsize='x-small')
#画像の表示
ax.set_title(test_results_dict['file_name'][0])
ax.imshow(img_ori)
fig.savefig(os.path.join(test_img_path, 'all_images.png'), dpi=500)images_show(6, 4)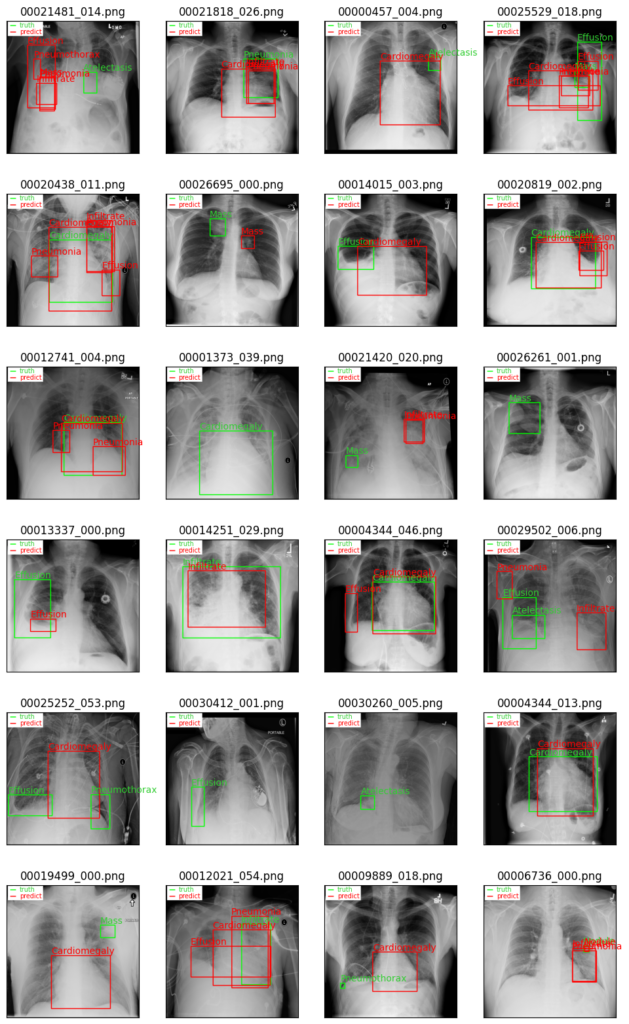
上記のように24枚の画像の結果を出力しています。正解Bboxを緑色で、予測Bboxを赤色で示しています。
予測結果を見てわかるように、正しく予測がなされているもの、予測が間違っているもの、そもそも予測結果の提案がなされていないものなど、多岐にわたります。
疾患によって予測精度が異なっており、特に、Cardiomegaly(心肥大)は比較的正しく予測がなされています。一方で、他の疾患に関しては一様に精度が低くなっています。
また、予測結果の提案がなされていないものに関しては、モデルの学習を行う中で、疾患を背景のレントゲン画像として認識してしまったためだと思われます。
特に、特徴量の小さ物体ほど背景と誤認する可能性が高く、胸部X線レントゲン画像における疾患の検出が困難であることを示唆している。
testデータの予測結果(全てのepochにおけるモデル)
epochごとに予測結果がどうなっているかを確認するため、全てのepochにおけるモデルの予測結果を出力しています。
def save_images(row_num, col_num, images_save_path):
fig, axes = plt.subplots(nrows=row_num, ncols=col_num, figsize=(12, 60), subplot_kw=({'xticks':(), 'yticks':()}))
for j, ax in enumerate(axes.flat):
test_results_dict = test_results[j]
#元画像の設定
img = (test_results_dict['image'][0] * 255).to(torch.uint8)
img_ori = np.transpose(img.cpu().numpy(), (1, 2, 0))
img_ori = cv2.cvtColor(img_ori, cv2.COLOR_RGB2BGR)
#正解labelごとにループ
for i in range(len(test_results_dict['truth_labels'])):
#正解bbox,labelの色を指定
t_label_index = test_results_dict['truth_labels'][i]
t_label_name = label_kind[int(t_label_index)]
#truth_bboxとtruth_labelを表示
cv2.rectangle(img_ori,
(int(test_results_dict['truth_boxes'][i][0]), int(test_results_dict['truth_boxes'][i][1])),
(int(test_results_dict['truth_boxes'][i][2]), int(test_results_dict['truth_boxes'][i][3])),
color=(0, 255, 0),
thickness=5
)
ax.text(int(test_results_dict['truth_boxes'][i][0]), int(test_results_dict['truth_boxes'][i][1]-15), t_label_name, color='limegreen')
#予測labelごとにループ
for i in range(len(test_results_dict['predict_labels'])):
#予測bbox,labelの色を指定
p_label_index = test_results_dict['predict_labels'][i]
p_label_name = label_kind[int(p_label_index)]
#predict_bboxとpredict_labelを表示
cv2.rectangle(img_ori,
(int(test_results_dict['predict_boxes'][i][0]), int(test_results_dict['predict_boxes'][i][1])),
(int(test_results_dict['predict_boxes'][i][2]), int(test_results_dict['predict_boxes'][i][3])),
color=(255, 0, 0),
thickness=5
)
ax.text(int(test_results_dict['predict_boxes'][i][0]), int(test_results_dict['predict_boxes'][i][1]-15), p_label_name, color='red')
#凡例の設定
cv2.rectangle(img_ori, (10, 10), (280, 120), color=(255, 255, 255), thickness=cv2.FILLED)
cv2.line(img_ori, (30, 40), (70, 40), color=(0, 255, 0), thickness=6, lineType=cv2.LINE_8, shift=0)
cv2.line(img_ori, (30, 90), (70, 90), color=(255, 0, 0), thickness=6, lineType=cv2.LINE_8, shift=0)
ax.text(100, 50, 'truth', color='limegreen', fontsize='x-small')
ax.text(100, 100, 'predict', color='red', fontsize='x-small')
#画像の表示
ax.set_title(test_results_dict['file_name'][0])
ax.imshow(img_ori)
fig.savefig(images_save_path, dpi=500)
plt.close(fig)
import random
import shutil
from PIL import Image, ImageDraw
all_images_dir = os.path.join(test_img_path, 'all_images')
os.mkdir(all_images_dir)
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
weight_dirs = glob(os.path.join(weight_folder_path, 'weight_*'))
for weight_dir in weight_dirs:
weight_name = os.path.splitext(os.path.basename(weight_dir))[0]
model.load_state_dict(torch.load(weight_dir))
test_results = []
model.eval()
with torch.no_grad():
for batch in test_loader:
image, target, name = batch
image = image.to(device)
predictions = model(image)
#print(predictions)
image = image.cpu()
truth_boxes = target['boxes'][0].cpu()
truth_labels = target['labels'][0].cpu()
predict_boxes = predictions[0]["boxes"].cpu()
predict_labels = predictions[0]["labels"].cpu()
predict_scores = predictions[0]["scores"].cpu()
dict_info = {'image':image, 'truth_boxes':truth_boxes, 'truth_labels':truth_labels, 'file_name':name,
'predict_boxes':predict_boxes, 'predict_labels':predict_labels, 'scores':predict_scores}
test_results.append(dict_info)
images_save_path = os.path.join(all_images_dir, f'images_{weight_name}.png')
save_images(18, 4, images_save_path)それでは、いくつか特定のepochにおける予測結果を確認していきます。
epoch=10の場合
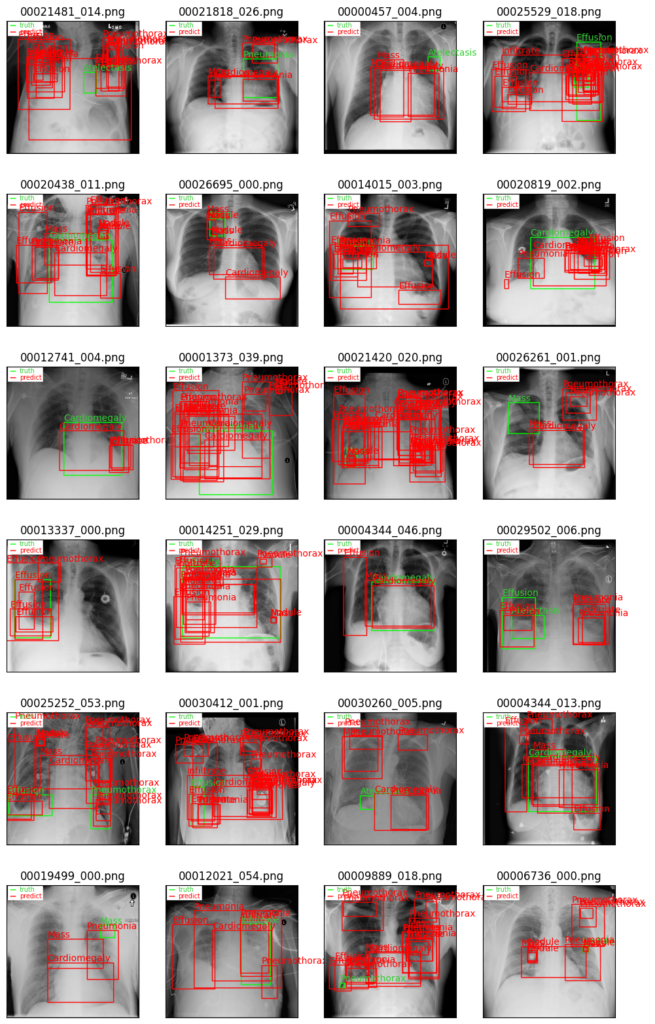
上記の結果のように、一つの画像に対して多くの予測結果が提案されています。
これは学習がまだ十分に進んでおらず、モデルが正解でない箇所を疾患として誤検出しているためだと考えられます。
scoreの値が低いものの表示させているため、scoreの値を閾値として予測結果の表示を選別すると、より良い結果になるかもしれません。
epoch=30の場合
エポック数が30になるとエポック数が10の時と比較して、かなり予測結果の提案が少なくなってきました。
中には、正しく予測ができているものも確認できます。
epoch=50の場合
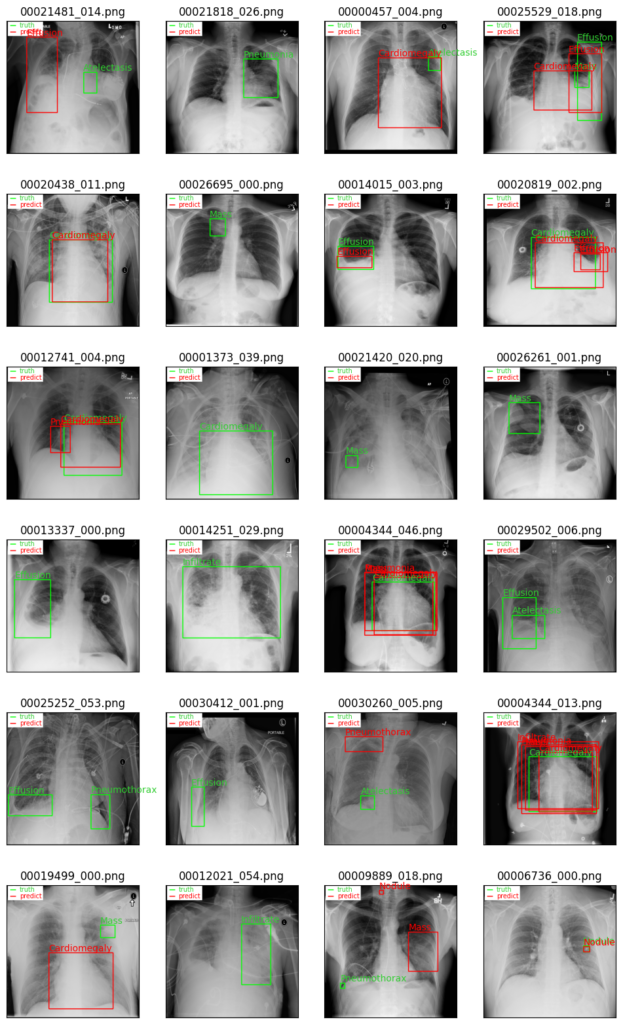
エポック数50のモデルでは予測の提案自体が少なく、精度も低いように感じます。
epoch=182の場合(最もval lossが小さい)
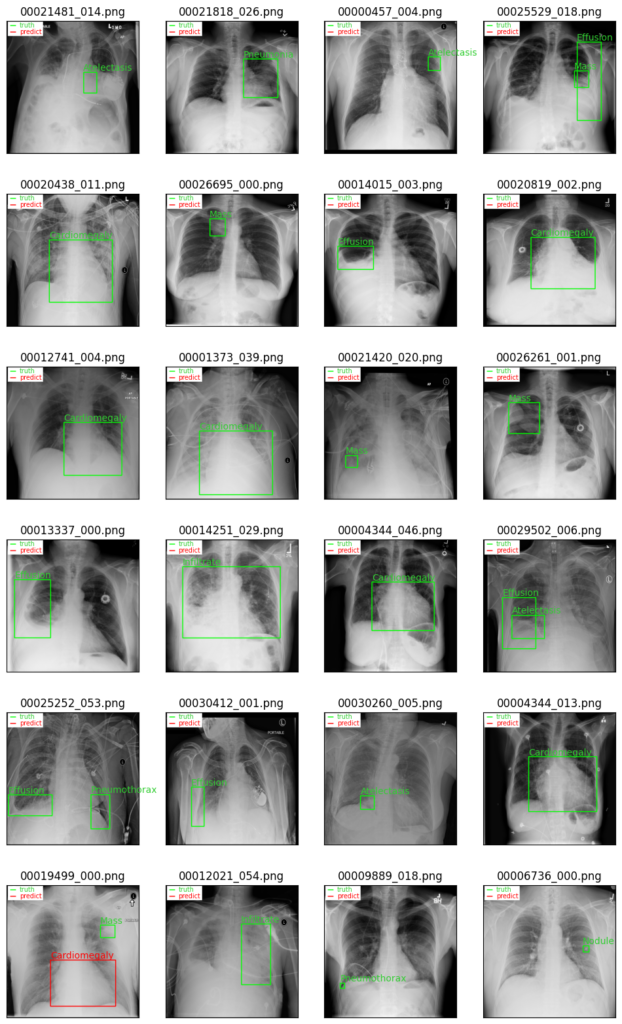
こちらはval lossの値が最も小さくなったエポック数182のモデルを使用した結果です。
一見してわかるように、ほとんど検出が行われおらず、モデルとしては最も良くない結果となっています。
総評
今回は正しく予測ができているものも確認できたものの、全体的に精度が低い結果となっています。
特に、エポック数が増加するにつれて、予測の提案数が減っていました。
学習過程にてval lossの値が十分に小さくなっていることを考慮すると、学習自体は問題ないように思えます。
しかし、学習を重ねるにつれて、モデルが疾患を背景として学習しており、疾患の検出が困難となっています。
実際に、私たちの目で見ても胸部X線レントゲン画像における疾患は識別しにくく、特徴が捉えづらくなっています。
そのため、パソコンが疾患を背景として認識するのも当然のことかもしれません。
次は、今回の予測結果をmAPと呼ばれる評価指標を用いて、定量的に評価していきます。

コメント